What Graphite is and is not
Graphite does two things:
- Store numeric time-series data
- Render graphs of this data on demand
What Graphite does not do is collect data for you, however there are some tools out there that know how to send data to graphite. Even though it often requires a little code, sending data to Graphite is very simple.
About the project
Graphite is an enterprise-scale monitoring tool that runs well on cheap hardware. It was originally designed and written by Chris Davis at Orbitz in 2006 as side project that ultimately grew to be a foundational monitoring tool. In 2008, Orbitz allowed Graphite to be released under the open source Apache 2.0 license. Since then Chris has continued to work on Graphite and has deployed it at other companies including Sears, where it serves as a pillar of the e-commerce monitoring system. Today many large companies use it.
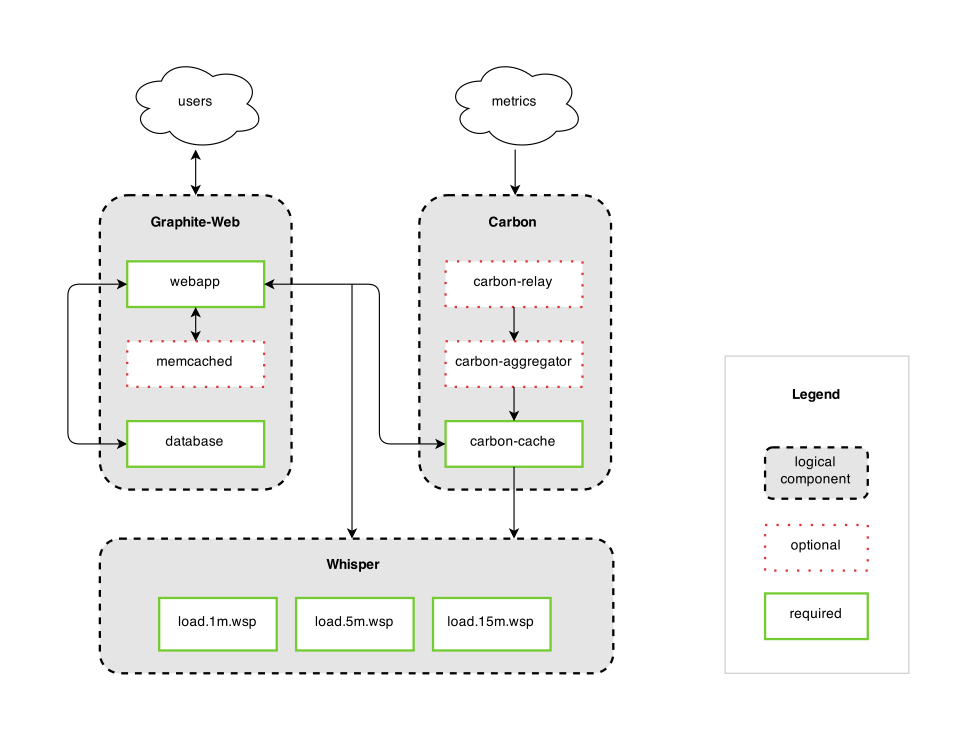
The architecture in a nutshell
Graphite consists of 3 software components:
- carbon - a Twisted daemon that listens for time-series data
- whisper - a simple database library for storing time-series data (similar in design to RRD)
- graphite webapp - A Django webapp that renders graphs on-demand using Cairo
Feeding in your data is pretty easy, typically most of the effort is in collecting the data to begin with. As you send datapoints to Carbon, they become immediately available for graphing in the webapp. The webapp offers several ways to create and display graphs including a simple URL APIfor rendering that makes it easy to embed graphs in other webpages.
What is Graphite?
Graphite is a highly scalable real-time graphing system. As a user, you write an application that collects numeric time-series data that you are interested in graphing, and send it to Graphite’s processing backend, carbon, which stores the data in Graphite’s specialized database. The data can then be visualized through graphite’s web interfaces.
The Carbon Daemons
When we talk about “Carbon” we mean one or more of various daemons that make up the storage backend of a Graphite installation. In simple installations, there is typically only one daemon,
carbon-cache.py. As an installation grows, the carbon-relay.py and carbon-aggregator.py daemons can be introduced to distribute metrics load and perform custom aggregations, respectively.All of the carbon daemons listen for time-series data and can accept it over a common set of protocols. However, they differ in what they do with the data once they receive it. This document gives a brief overview of what each daemon does and how you can use them to build a more sophisticated storage backend.
carbon-cache.py
carbon-cache.py accepts metrics over various protocols and writes them to disk as efficiently as possible. This requires caching metric values in RAM as they are received, and flushing them to disk on an interval using the underlying whisper library. It also provides a query service for in-memory metric datapoints, used by the Graphite webapp to retrieve “hot data”.carbon-cache.py requires some basic configuration files to run:- carbon.conf
- The
[cache]section tellscarbon-cache.pywhat ports (2003/2004/7002), protocols (newline delimited, pickle) and transports (TCP/UDP) to listen on. - storage-schemas.conf
- Defines a retention policy for incoming metrics based on regex patterns. This policy is passed to whisper when the
.wspfile is pre-allocated, and dictates how long data is stored for.
carbon-cache.py instance may not be enough to handle the I/O load. To scale out, simply run multiple carbon-cache.py instances (on one or more machines) behind a carbon-aggregator.py or carbon-relay.py.carbon-relay.py
carbon-relay.py serves two distinct purposes: replication and sharding.When running with
RELAY_METHOD = rules, a carbon-relay.py instance can run in place of a carbon-cache.py server and relay all incoming metrics to multiple backend carbon-cache.py‘s running on different ports or hosts.In
RELAY_METHOD = consistent-hashing mode, a DESTINATIONS setting defines a sharding strategy across multiple carbon-cache.py backends. The same consistent hashing list can be provided to the graphite webapp via CARBONLINK_HOSTS to spread reads across the multiple backends.carbon-relay.py is configured via:- carbon.conf
- The
[relay]section defines listener host/ports and aRELAY_METHOD - relay-rules.conf
- With
RELAY_METHOD = rulesset, pattern/servers tuples in this file define which metrics matching certain regex rules are forwarded to which hosts.
carbon-aggregator.py
carbon-aggregator.py can be run in front of carbon-cache.py to buffer metrics over time before reporting them into whisper. This is useful when granular reporting is not required, and can help reduce I/O load and whisper file sizes due to lower retention policies.carbon-aggregator.py is configured via:- carbon.conf
- The
[aggregator]section defines listener and destination host/ports. - aggregation-rules.conf
- Defines a time interval (in seconds) and aggregation function (sum or average) for incoming metrics matching a certain pattern. At the end of each interval, the values received are aggregated and published to
carbon-cache.pyas a single metric.
carbon-aggregator-cache.py
carbon-aggregator-cache.py combines both carbon-aggregator.py and carbon-cache.py. This is useful to reduce the resource and administration overhead of running both daemons.carbon-aggregator-cache.py is configured via:- carbon.conf
- The
[aggregator-cache]section defines listener and destination host/ports. - relay-rules.conf
- See carbon-relay.py section.
- aggregation-rules.conf
- See carbon-aggregator.py section.
The Whisper Database
Whisper is a fixed-size database, similar in design and purpose to RRD (round-robin-database). It provides fast, reliable storage of numeric data over time. Whisper allows for higher resolution (seconds per point) of recent data to degrade into lower resolutions for long-term retention of historical data.
Data Points
Data points in Whisper are stored on-disk as big-endian double-precision floats. Each value is paired with a timestamp in seconds since the UNIX Epoch (01-01-1970). The data value is parsed by the Python float() function and as such behaves in the same way for special strings such as
'inf'. Maximum and minimum values are determined by the Python interpreter’s allowable range for float values which can be found by executing:python -c 'import sys; print sys.float_info'
Archives: Retention and Precision
Whisper databases contain one or more archives, each with a specific data resolution and retention (defined in number of points or max timestamp age). Archives are ordered from the highest-resolution and shortest retention archive to the lowest-resolution and longest retention period archive.
To support accurate aggregation from higher to lower resolution archives, the precision of a longer retention archive must be divisible by precision of next lower retention archive. For example, an archive with 1 data point every 60 seconds can have a lower-resolution archive following it with a resolution of 1 data point every 300 seconds because 60 cleanly divides 300. In contrast, a 180 second precision (3 minutes) could not be followed by a 600 second precision (10 minutes) because the ratio of points to be propagated from the first archive to the next would be 3 1/3 and Whisper will not do partial point interpolation.
The total retention time of the database is determined by the archive with the highest retention as the time period covered by each archive is overlapping (see Multi-Archive Storage and Retrieval Behavior). That is, a pair of archives with retentions of 1 month and 1 year will not provide 13 months of data storage as may be guessed. Instead, it will provide 1 year of storage - the length of its longest archive.
Rollup Aggregation
Whisper databases with more than a single archive need a strategy to collapse multiple data points for when the data rolls up a lower precision archive. By default, an average function is used. Available aggregation methods are:
- average
- sum
- last
- max
- min
Multi-Archive Storage and Retrieval Behavior
When Whisper writes to a database with multiple archives, the incoming data point is written to all archives at once. The data point will be written to the highest resolution archive as-is, and will be aggregated by the configured aggregation method (see Rollup Aggregation) and placed into each of the higher-retention archives. If you are in need for aggregation of the highest resolution points, please consider using carbon-aggregator for that purpose.
When data is retrieved (scoped by a time range), the first archive which can satisfy the entire time period is used. If the time period overlaps an archive boundary, the lower-resolution archive will be used. This allows for a simpler behavior while retrieving data as the data’s resolution is consistent through an entire returned series.
Comments
Post a Comment